출처: LG Aimers 강의 (https://www.lgaimers.ai/)
gradient descent algorithm
gradient: 기울기 / 함수를 미분하여 얻는 term으로 해당 함수의 변화하는 정도를 표현하는 값
error surface에서 최소인 포인트를 찾아가는 것이 목적이다.
error surface에서 최소인 포인트에서는 gradient가 0이다.
gradient descent에서는 gradient가 0인 지점까지 반복적으로 세타를 바꿔나가면서 탐색을 해야함, gradient(함수의 변화도)가 가장 큰 방향으로 이동한다
gradient descent algorithm은 경우에 따라 local optimum(지역 최소치)만을 달성하기 쉽다.
- Global optimum: 전체 error surface에서 가장 최소인 값을 갖는 지점
- local optimum: 지역에선 최소일 수 있지만 전체 영역을 놓고 봤을 때 최소가 아닐 수도 있는 지점
- hyper parameter: 사전에 설정하는 파라미터 값
- learnable parameter: 모델이 학습하면서 바뀌는 파라미터 값
gradient descent와 normal equation 사이에는 차이가 있다.
gradient descent는 여러 번의 반복적인 과정을 수행을 통해 해를 얻어 나가는 것
normal equation는 한번에 1step으로 해를 구한다
하지만 그 해를 구하기 위해서는 다음과 같은 매트릭스를 곱해야하기 때문에
샘플 사이즈가 굉장히 늘어나게 되는 경우에 inverse 매트릭스 를 구하기가 굉장히 어려워지는 문제가 발생하게 된다.
반면에 gradient descent algorithm과 같은 경우는 설령 n이 굉장히 크더라도 우리가 반복적으로 해를 구해 나갈 수 있다.
Model optimization을 위해선 normal equation을 이용해 파라미터를 구할 수도 있지만 보통 최근 Machine Learning 문제에선 Gradient descent algorithm을 통해 iterative하게 솔루션을 찾아나가게 된다.
이러한 해는 interpretable(해석 가능)하고 간편하기 때문에 이 model은 우리가 문제를 가장 처음으로 접근하기에 좋은 방식이라고 볼 수 있다.
Batch gradient descent algorithm
local optimum에 취약하지만 어느정도 수렴되는걸 볼 수 있음
단점: 업데이트 할 때 전체 샘플 m개를 모두 고려해야 한다
⇒ m을 극단적으로 1로 바꾼 것이 Stochastic graidient descent이다.
샘플 한개마다 업데이트를 하는 것
Stochastic graidient descent (SGD)
SGD는 Batch gradient descent algorithm보다 빠르게 반복할 수 있다는 장점이 있다.
각 샘플 하나하나마다 계산을 통해 파라미터를 연산하기 때문에 노이즈의 영향을 받기 쉽다는 단점이 있다.
수렴하는 과정에서 많은 오실레이션(주기적으로 변하는 진동)이 발생하는 것을 알 수 있다.
gradient descent algorithm은 파라미터의 초기 포인트에 따라서 local minimum에 빠지기 쉽다.
*** 그냥 gradient descent algorithm 라고 하면 Batch gradient descent algorithm 이라고 보면 된다
⇒ Batch gradient descent algorithm의 Batch가 배치 프로그램의 배치라고 생각하면… 배치가 일괄처리 느낌이니까 한번에 다 처리한 후 업데이트라고 보면 된다!
gradient descent 가 local minima 에 빠지지 않도록 하는 효과적인 방법들
딥러닝과 같이 복잡한 모델을 사용하면 error surface가 복잡해서 local optima에 빠지기 쉬운 것으로 알려져있다.
suboptimal한 문제점들을 해결하기 위해 기존의 gradient descent algorithm에서 다양한 변형 algorithm들이 개발되었다.
그중 가장 대표적인 방식이 momentum을 이용하는 것이다.
Momentum
Momentum: 과거에 Gradient가 업데이트 되어오던 방향 및 속도를 어느 정도 반영해서 현재 포인트에서 Gradient가 0이 되더라도 계속해서 학습을 진행할 수 있는 동력을 제공하게 되는 것
⇒ 이러한 방식은 low pass filtering 연산이기 때문에 현재 포인트에서의 saddle point나 작은 noise gradient 값의 변화가 안정적으로 수렴할 수 있게 바뀌게 된다.
SGD + momentum
설령 local minumum이나 saddle point에서 gradient가 0이 되는 지점이 발생하더라도 과거에 이어오던 momentum 값을 반영해서 계속해서 학습을 진행할 수 있게 된다.
momentum을 이용하는 gradient descent에서 좀 더 발전한 것이 nestrov momentum 방식이다.
nestrov momentum
기존의 방식과 다르게 우선 gradient를 먼저 평가하고 업데이트를 해주게 된다.
그래서 look ahead gradient step을 이용한다고 얘기한다.
actual step, momentum step을 계산을 할 때 미리 momentum step만큼 이동한 지점에서 lookahead gradient step 을 계산하기 때문에 그 momentum step과 gradient step 의 합으로 actual step을 계산하게 된다
(Module4.3 9분 30초쯤 설명)
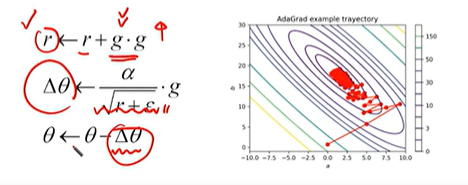
AdaGrad
각 방향으로 learning rate를 적응적으로 조절해서 학습 효율을 올리게 된다
r은 기존의 값 r에 gradient의 제곱을 더해가며 업데이트를 하게 된다
gradient의 제곱이기 때문에 양수라서 r은 점점 커지게 된다.
r은 델타세타의 분모의 term으로 들어가기 때문에 r이 커지면서 델타세타는 점점 값이 작아지게 된다
어느 한 방향으로 gradient가 크다라는 것은 이미 그 방향으로 학습이 많이 진행되었다라는 것을 의미할 수 있다
어느 한 방향으로 학습이 많이 진행되어서 gradient 값이 크다는 것은 델타 세타의 값이 작아져서 수렴하는 속도를 줄이게 되는 것을 말한다.
아직 학습이 적게 진행 되어서 r 값이 작다 하면 그 방향으로는 세타값을 크게 해서 수렴의 속도를 보다 빠르게 할 것이다.
AdaGrad와 같은 방식의 단점
gradient 값이 계속해서 누적됨에 따라서 learning rate 값이 굉장히 작아지게 된다는 것이다.
learning rate 값이 작아지면 학습이 일어나지 않을 것이다.
⇒ 이런 방식을 수정한 것이 RMSProp algorithm이다.
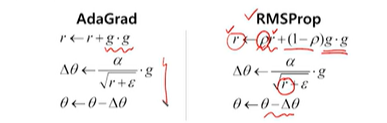
RMSProp
r을 업데이트 할 때 바로 gradient의 제곱을 그대로 곱하는게 아니라
r의 값을 과거의 r만큼의 로우(p) factor를 곱해서 어느정도 조절하게 된다.
그 조절된 값인 r은 분모에 들어가기 때문에 과거(=AdaGrad)와 같이 극단적으로 gradient값이 누적됨에 따라 세타 값이 줄어드는 것이 아니라
RMSProp 방식에선 어느정도 완충된 형태로 학습 속도가 줄어든다고 생각할 수 있다.
머신러닝, 딥러닝을 공부하며 가장 많이 접하게 될 gradient descent algorithm은 Adam이 될 것이다.
=> 실제로 해보니 그렇다... 학원에서 코딩을 할 때 Adam과 SGD와 AdamW를 많이 썼었다.
Adam
Adaptive moment estimation
RMSProp + Momentum 방식
- 첫번째 모멘텀을 계산한다
- RMSProp 방식으로 두번째 모멘텀을 계산한다
- bias를 correction한다
통계적으로 보다 안정된 학습을 위해서 bias를 correction하는 과정 - 파라미터를 업데이트함

Learning rate scheduling
하이퍼파라미터 알파(=step size)를 학습 과정에 따라서 조절하는 것이다.
- low learning rate에서는 천천히 수렴하게 되지만 loss를 줄일 수가 있다.
- 반대로 high learning rate의 경우엔 학습이 진행될수록 loss가 줄어들지 않지만 보다 더 빠르게 학습을 진행할 수 있다는 장점이 있다.
⇒ 이 두개의 장점을 혼합한 것! 학습 단계마다 적응적으로 조절을 해나갈 수 있다.
step size인 알파를 학습 과정에 따라서 점차 줄여나가는 것이다.
그러면 초기에는 우리가 학습을 빠르게 진행을 할 수 있는 반면에 알파값이 늘어남에 따라서 cost가 더이상 줄어들지 않는 문제를 learning rate를 점차 더 줄임으로써 학습이 용이하게끔 할 수가 있는 것이다.
model의 과적합 문제를 해결하는 최적화 과정에서의 몇 가지 팁 - Regularization
Model 과적합 문제: Model이 지나치게 복잡하여, 학습 Paramaeter의 숫자가 많아서 제한된 학습 샘플에 너무 과하게 학습이 되는 것
예를 들어 집값을 추정하는 regression model에서 입력 feature의 숫자가 지나치게 많아진다면 항상 좋은 것일까?
=> 그렇지 않다. 일부 입력 변수들은 상호 간에 dependent 할 수도 있다.
그러나 입력 feature의 숫자가 많아지게 된다면 더욱 parameter의 개수가 많아지게 되고 그것은 우리가 curse of dimension problem에 의해서 data의 개수가 더 많아지게 된다는 것이다
하지만 우리가 실질적으로 실제 환경에서는 data를 충분히 늘릴 수가 없기 때문에 이 model이 overfitting이 되는 문제가 발생하게 된다.
MSE(mean-squared-error)와 같은 경우에는 이러한 noise, outlier에 민감한 특성을 갖게 된다.
⇒ 이러한 문제를 해결할 수 있는 대표적 방법: Regularization 방식
Regularization : 복잡한 모델을 사용하더라도 학습과정에서 모델의 복잡도에 대한 패널티를 줘서 모델이 overfitting되지 않도록 하는 방식 / 어떤 특정 파라미터의 중요성에 따라서 학습을 진행하는 동안에 오버피팅을 피하기 위해 모델의 복잡도를 줄이기 위한 방식
모델은 가급적 적은 파라미터의 개수를 사용하면서 주어진 문제의 샘플들을 피팅을 하고자 할 것이고, 그렇게 해서 오버피팅의 문제를 피할 수가 있을 것이다.
마치 Regularization은 머신러닝에서의 비지도학습 중 차원축소와 비슷한 느낌 같다.
feature들끼리 의존적이여서 모델의 복잡도를 줄여주기 위해 하는 차원축소와 비슷한 느낌의 개념 🤔
'인공지능' 카테고리의 다른 글
| AI로 무엇을 해야하고 무엇을 하면 안될까 (0) | 2024.01.20 |
|---|---|
| 네이버 코칭스터디 - Data Science Projects 2024 (0) | 2024.01.06 |
| LG Aimers 선정됐다~! (0) | 2023.12.31 |
| 렐루 함수(ReLU), XAI (0) | 2023.11.23 |
| transformer는 정말 다용도다.. (0) | 2023.11.22 |